Like any business, we have certain files that need to be accessed by the public - compliance documents, marketing materials, helpful instructions, miscellaneous stuff on our website, etc.
We attempted to do this with just SharePoint. It didn't work. I explain more about that below, but if you want, you can jump straight to our current solution (involving SharePoint, Azure Storage, and Cloudflare).
SharePoint links are great except when they aren't
When we started with SharePoint, our first idea was to generate anonymous links to files in SharePoint and use those links directly on our website.
This was cool because employees did not have to log in to the website management portal to update files on the website - you could just update the file in SharePoint. We could also include these links in email signatures, embedded PDFs, or anywhere else, and the links would (theoretically) always point to the current version of the file.
However, there were some issues:
Links break
SharePoint links will sometimes stop working for no apparent reason, and without any notification. We wouldn't know that a link was broken until we discovered it or somebody told us - and the only fix was to create a new link.
And yes, we did double-check our SharePoint link-expiration setting.

Office Online apps are not always what you want
SharePoint links will, by default, open Office documents in the corresponding online app - in other words, if you generate a link to an Excel document, the link will open the file in the online version of Excel instead of downloading the file to your computer. To prevent public modification of the files, we generated the SharePoint links as read-only, and this combined with the online app often made things pretty confusing. Also, sometimes the intended use of a file requires that it be downloaded, and this wasn't something you could do intuitively in the web app especially if you weren't already familiar with the Office Online apps (e.g. many of our older clients).
A similar thing happens with PDF files, which are displayed in SharePoint's built-in PDF viewer by default. Of course, you can click a button to download the file, but sometimes we just did not want the SharePoint viewer.
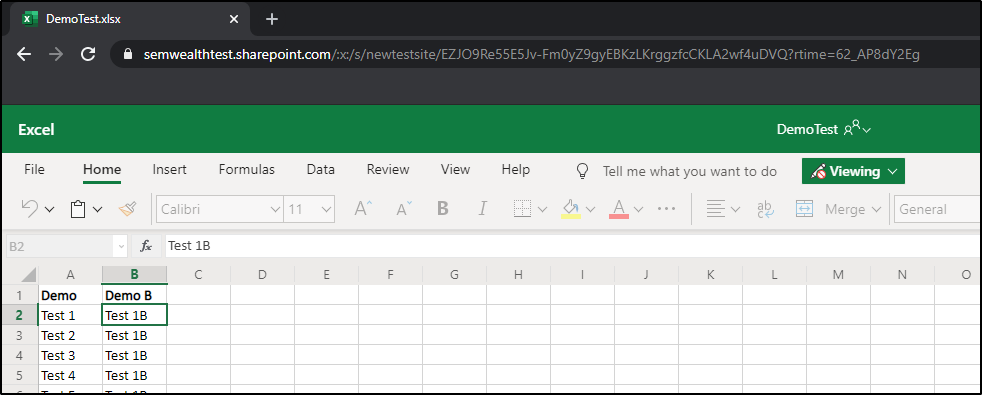
There is a workaround for this - add download=1 to the URL as a query parameter. In practice, this was a bit unwieldy for our users - you have to generate the link, then manually add something to the end of it. Also, sometimes the link already has a query parameter so you would have to add &download=1 instead of ?download=1. Users expected the link to "just work" (and rightfully so), and this solution was not doing that.
Which link do I use?
You can also shoot yourself in the foot if you copy the URL in the address bar instead of the link that SharePoint gives you. Intuitively you might think that if you already generated an anonymous link to a file, you can just browse to that same file in SharePoint and copy the URL in the address bar - but that is not the case. The generated, externally sharable URL is different than the normal server-relative URL. If someone outside of the organization attempts to use the server-relative URL and doesn't have a Microsoft 365 account (or isn't signed in to one), it will ask them to sign in - which is the exact opposite thing that we want for public files.
This can be overcome with user training, and if it was the only issue we would be able to deal with it.
Can I be sure that the link actually works?
Employees would often test a link and think that it worked, because it worked for them. But there's another easy way to shoot yourself in the foot here: If you're logged in to SharePoint when testing a link, you're not actually accessing the link anonymously - you're accessing it as yourself, an authenticated SharePoint user. This makes it easy to think the URL you've copied will work, even though it might not work for an unauthenticated user (e.g. a client clicking the link on our website). Combined with the above "which link do I use" issue, this because pretty annoying for our users.
There is a workaround for this too - test all links in a private/incognito tab to simulate accessing them "anonymously" - but it's yet another thing to remember.
While SharePoint links had promise, we ended up troubleshooting broken links quite often. This left us pretty frustrated with a situation that was supposed to make things better.
SharePoint is not a CDN
The core issue was that we were trying to use SharePoint as a CDN, but SharePoint is not meant to be used like that. To be clear, SharePoint/OneDrive links (even anonymous links) are great if you need to quickly share a file, temporarily, and with only a few people - which we still do. Just not for making files available indefinitely to the public.
I had been toying with the idea of creating our own CDN by using Azure blob storage behind Cloudflare, but I had some concerns:
- Training employees to use Azure Storage Explorer, which is yet another application
- Training employees to get the CDN-relative URL
- Figuring out how to set permissions in Azure correctly
- etc.
Most importantly, this solution would undermine the reasons we wanted to use SharePoint for public files this in the first place. From a user's perspective, we might as well just go back to hosting our files in our website's CMS. We did eventually think of a better solution, though:
Synchronize a document library with a blob container
As it turns out, we can use SharePoint to interface with Azure blob storage and get the benefits of both. We can maintain files on the CDN, share files anonymously via SharePoint links, or both - and users only need to use SharePoint.
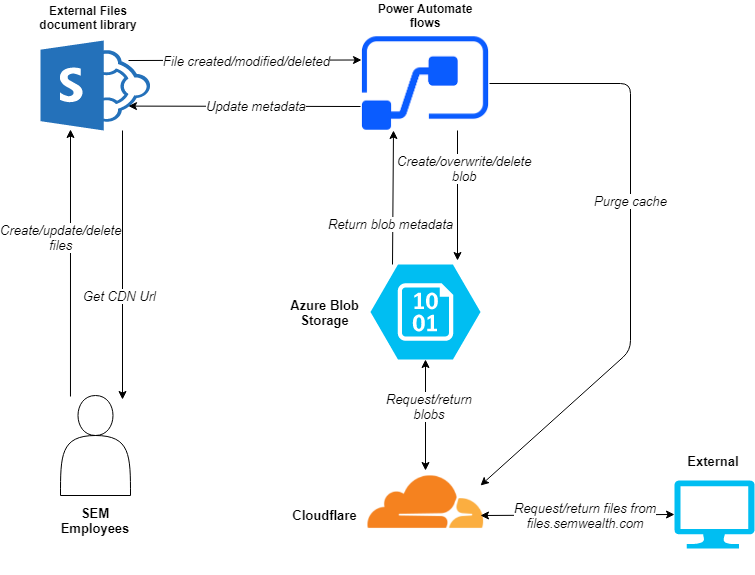
Overview
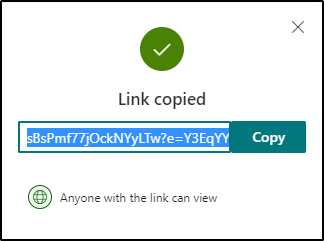
We created a SharePoint site whose sole purpose is to hold files which need to be shared externally (i.e. publicly). This site allows anonymous external links to be generated (i.e. "anyone with the link can view"). All other sites have anonymous external sharing disabled.
In this site's document library, we also created some custom metadata columns. One of these columns is a Yes/No column titled Sync to CDN. When this column is set to Yes, it kicks off a Power Automate flow which copies the file to an Azure blob container. This blob container has a custom domain (files.semwealth.com) and sits behind Cloudflare, so HTTP requests do not actually hit the blob container very often, which minimizes cost and makes files highly available around the world. After the file is copied from SharePoint to the blob container, another custom metadata column is populated with the CDN-relative URL (something like files.semwealth.com/[filename]).
If a file is modified in this document library and its Sync to CDN value is Yes, the flow copies the file to the blob container again, overwriting the existing file, and then purges the file from Cloudflare's cache so that the updated file is immediately available. This allows users to simply overwrite an existing file in the document library - and within about a minute the file on the CDN will also be updated.
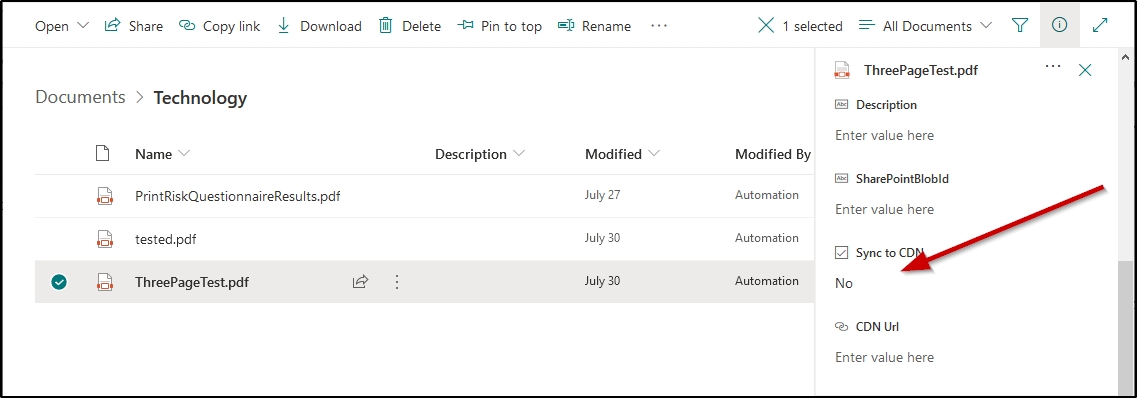
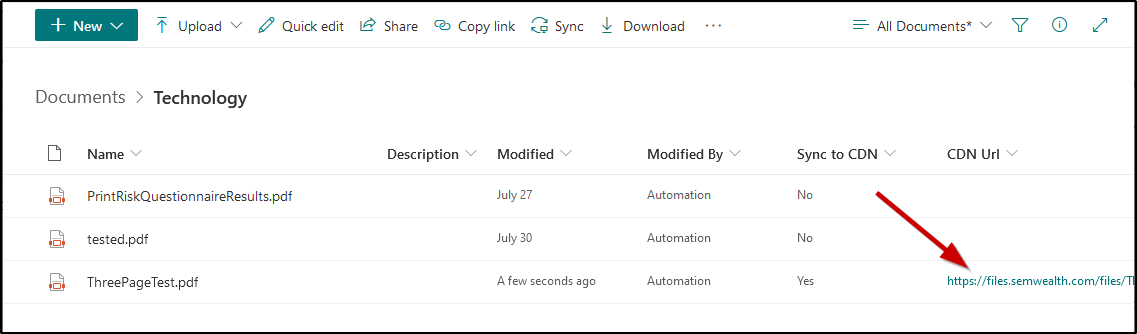
If the Sync to CDN column is changed to No or the file is deleted from the document library, the file is removed from the blob container and purged from Cloudflare.
Document library set up
We set up a communication site called "External Files". There is one document library in this site. This document library has several folders in it, one for each department at SEM. These folders have specific permissions which allow anyone to view the files, but only members of that department can create, delete, or modify files within that folder. This means that certain departments can be wholly responsible for curating their public files without fear that another department might mess something up.
To facilitate the synchronization with the Azure blob container, we created the following metadata columns:
- CDN Url - Hyperlink column
- Sync to CDN - Yes/No column
- SharePointBlobId - Single line of text column
Azure blob container and CDN set up
This part was relatively easy. We just created a new a storage account in Azure (standard tier), created a new blob container, and mapped a custom domain.
The only issue here was with CNAME record verification to apply the custom domain. This was because we had the custom subdomain proxied through Cloudflare when trying to perform the verification. We switched the subdomain to "DNS only" in Cloudflare, verified the domain, and then switched it back to proxied.
Power Automate and Azure Blob Storage
There is an Azure Blob Storage connector in Power Automate, which is awesome. Less awesome is that it's a "premium" connector, and in order to use "premium" connectors you need to have a paid Power Automate license. Unfortunately, this license is not included in most plans, even Microsoft 365 E3. I thought I could get around this by using the HTTP connector and creating my own requests, but the HTTP connector is also a premium connector. I don't like that you have to pay for another license to get this functionality, but that's the way it is.
I was able to turn this into something positive though - for a while I had been thinking about the best way to handle Power Automation flows that really should not be using the account of a normal user. In the world of on-prem systems, you would just use a dedicated system account. In Microsoft 365, you can't do this without paying to license the account the same way you would a "real" user. Since we needed an additional Power Automate license for this project anyway, I figured this would be a good time to create a dedicated "automation" account.
Automation user
I created a new Office 365 account named "Automation" and gave it Power Automate (per user) and Microsoft 365 Business Standard licenses so that it could access SharePoint and whatever else we use it for in the future. The account password is really long and randomly generated, and only a few people have access to the credentials in our password manager. I also set up and enforced MFA such that it is required for all login attempts.
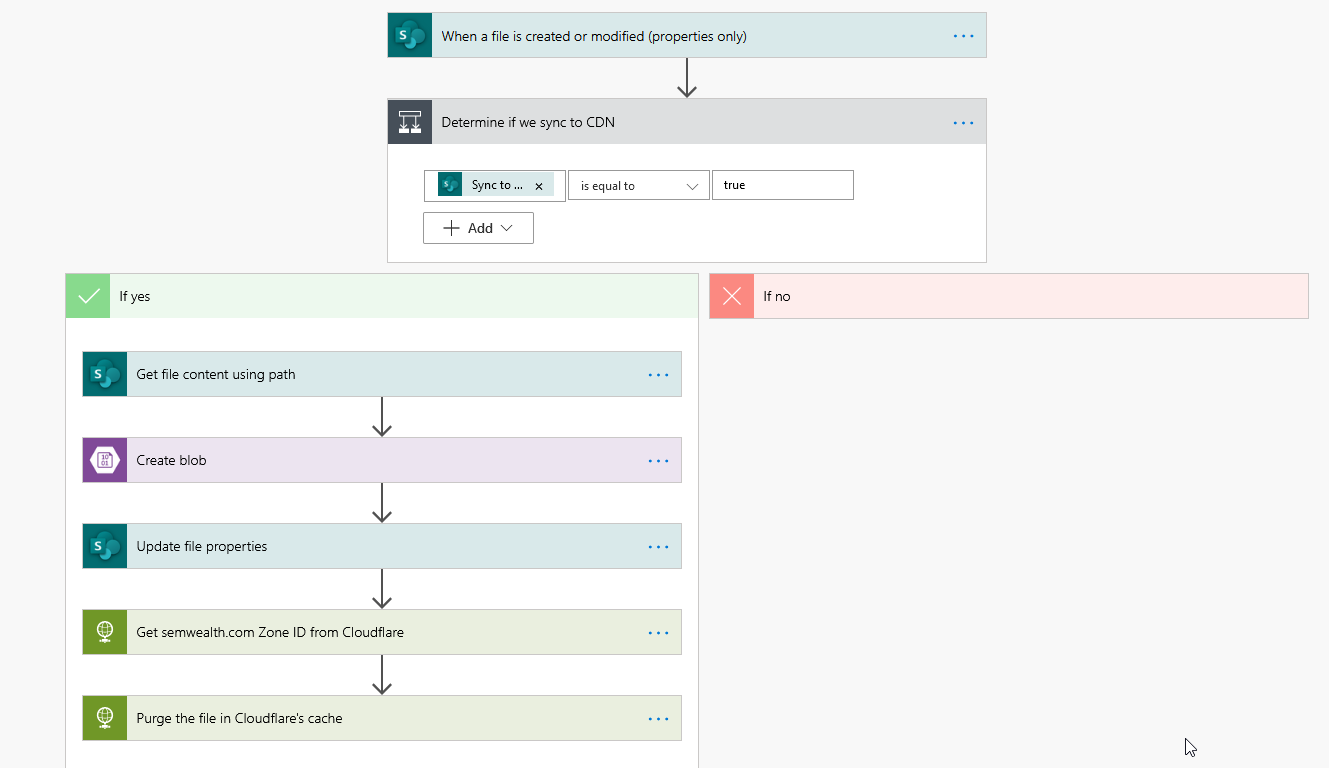
Power Automate flow #1
We actually have two flows. The first one runs whenever a file is created or modified in the External Files document library. It checks to see if the Sync to CDN column is set to Yes, and if so:
- copies the file to the Azure Blob container (overwriting an existing blob with the same name if one exists)
- updates the file's CDN Url and SharePointBlobId columns in the document library
- tells Cloudflare to purge the file from its cache (using their RESTful API) so that the most current version of the file is what Cloudflare serves .
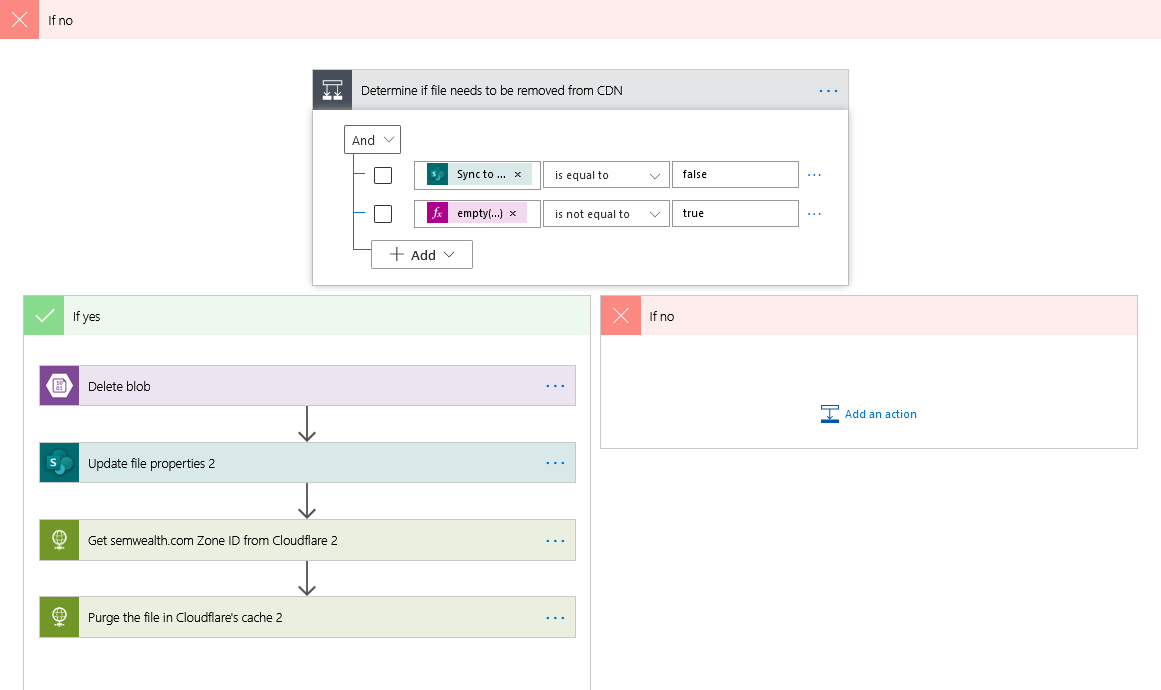
If the Sync to CDN column is set to No, the flow will:
- check to see if the file needs to be removed from the blob container (i.e. is there something in the SharePointBlobId column).
- if so, look for a blob which matches the SharePointBlobId value and deletes that blob
- Clear the file's SharePointBlobId and CDN Url columns.
- purges the file from Cloudflare's cache to make sure it is no longer available.
Power Automate flow #2
The second flow allows us to deal with files that are deleted in the document library. Initially I tried to trigger the flow when a file is deleted in the document library, but the trigger action doesn't return custom metadata properties for the deleted file (because it runs after the file is already deleted). This means that there's no way to match the deleted file with a blob in the blob container.
Our solution was to have the flow run once per night. When it runs, the flow will:
- gets a list of all the blobs in our blob container.
- for each of those blobs, look in the SharePoint document library to see if there is a file whose SharePointBlobId matches the blob's Id.
- if no match is found, the blob is deleted and the Cloudflare cache is purged.
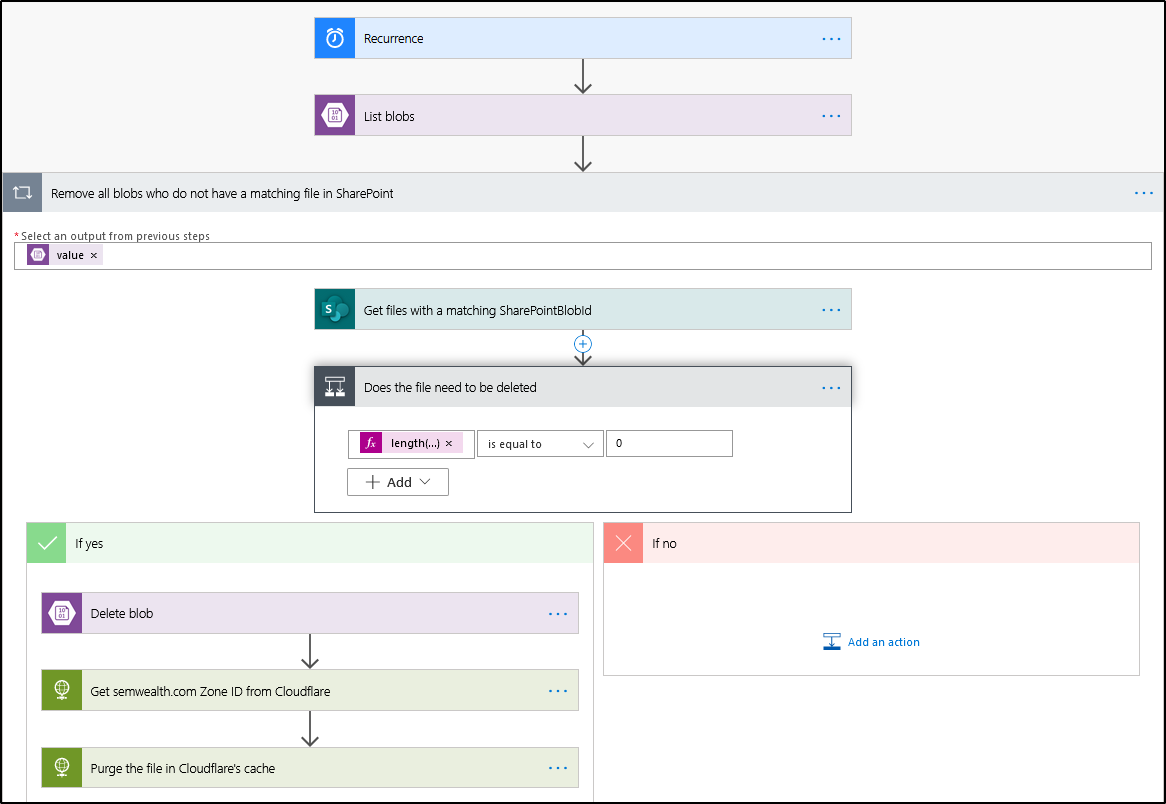
This means that users can delete files from the SharePoint document library and those files will be removed from the CDN by the next morning. If a file needs to be removed from the CDN before then, our users have been trained to first change the file's Sync to CDN column to No - which will trigger the first flow and pull the file off the CDN within about 60 seconds. The file can then be deleted if necessary.
Another thing we've had to train our users on: it takes up to 60 seconds for flow #1 to trigger, which means it could take just over 60 seconds before we get a value in the CDN Url column and the file is available/updated on the CDN. This seems like "normal" behavior for flows and I don't think we'll ever be able to expect it to run instantly.
DLP
From a security perspective, one concern I had was how to make sure that files with PII were not shared externally. For SharePoint links, this was easy - just create a Data Loss Prevention policy which prevents external sharing for any files containing the sensitive information we're concerned about. We already had this policy in place prior to this project.
Preventing files from going to the CDN was not as smooth unfortunately. Using a combination of DLP policies, Power Automate, and even Retention tags I still could not figure out how to restrict certain metadata columns (e.g. the Sync to CDN column) based on if the file contains sensitive information. If anyone knows how to do this, please let me know!
Instead, I added another DLP policy which looks specifically at the External Files site. If any files contain PII, I get a notification and investigate it immediately. There are situations where a file does actually need to be shared publicly and has been detected to contain PII (e.g. instructions with example data that looks like real PII, false positives, etc), so this also allows us to make exceptions on a case-by-case basis.
Summary
The ability to efficiently and securely manage our public files was a big win for us. If you have any questions, feel free to contact me or drop a comment on this article.